蕭乃沂[1]
國立政治大學公共行政學系副教授
郭毓倫[2]
國立政治大學公共行政學系博士候選人
〈摘要〉
網路輿論由於其大量、即時、與傳播速度,已成為反映且影響公共政策議題的重要來源,然而透過網路輿論掌握其聲量與情緒意向(或好感度),仍不足以作為政策對話與討論的基礎,因為目前仍無法萃取多元立場與其背後的理由與證據,除了演算法在語意分析上的侷限,也尚未鑲嵌於政策審議流程與其他輿論分析方法妥善配合,這也成為網路輿論分析作為公共政策分析審議的關鍵瓶頸。
本文以實際案例凸顯上述的現況與瓶頸,規劃實作網路輿論分析流程,包括以好感度(或情緒)與態度意向(或立場)為分析焦點。除了展示初步成果,也據以討論公共政策實務與研究意涵。透過實際執行經驗與成果,除了強調網路輿情的情緒與立場分析如何可能善用於循證政策分析,也設想如何與其他政策資料蒐集與分析方法交互搭配,作為後續實務與研究的參考。
關鍵字:網路輿情、自然語言處理、機器學習、循證決策、公共政策
壹、前言
消費者或公民個體在網際網路虛擬空間中發表意見,早已成為數位時代中的常態,相較於透過電話調查或訪談所蒐集的意見,網路輿論/輿情(online/Internet public opinions)最主要的優勢在於其大量與即時性,且由於不需面對明顯的訪談者,匿名或假名發言者也相對能「沒有戒心」地充分表達情緒態度與言論內容,因此民間企業與非營利組織也逐漸熟悉如何善用這些特質。
對於各國政府組織而言,網路輿情也已成為數位時代影響政府與公共政策的主要來源之一,以線上公共政策議題討論區的言論為實證資料,Noet(2017)發現線上討論不只能反映網路民眾對於特定議題的情緒及抱怨,搭配議題特質與適當的輔助程序,也能夠在其分歧意見的相互激盪中逐步收斂。歷經逾 20 餘年的發展,民眾從透過政府組織的電子郵件信箱反映其抱怨、網路公共論壇的討論品質、乃至於社群媒體(Twitter、Facebook、我國 PTT 等)串連互動,Luna-Reyesm與Najafabadi(2017)指出未來值得關注的研究方向之一,即為如何透過虛擬空間中各種來源的網路言論,提升公共政策議題的審議與對話品質,並與實體公民參與程序互補與整合。
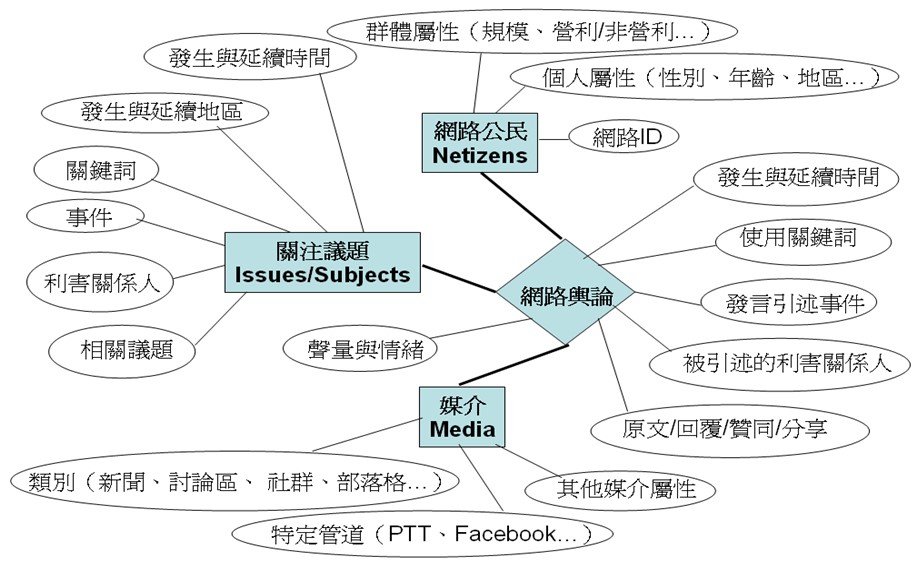
蕭乃沂等(2014)以我國當時備受爭議的自由經濟示範區為政策議題範例,界定網路輿論的三個主體(entity,以方框粗體文字表示)為網路公民發言者(netizens)、受關注議題(issues)、以及網路媒介(Internet media),此三個主體的屬性在圖 1 中以橢圓文字顯示,代表與其有關的基本特質,例如網路公民有其網路帳號(ID)、個人與群體屬性,不過由於其匿名性而不見得可以完全揭露,同樣地,媒介與受關注議題也有其個別屬性(如圖 1 中的議題關鍵詞、回覆分享情形等)。
相較於純粹的好感度或情緒宣洩,將網路輿情分析運用於公共政策審議的研究與實務上,目前仍有若干亟待釐清的議題與突破的挑戰。首先是運用自動化語意分析演算法判斷網路民眾對於特定政策議題的評論,如同所有的網路搜尋引擎,除了在萃取言論與議題的可能會有相關性(relevance)誤差,目前仍以正面與負面的情緒(sentiment)較有信度與效度,但是對於言論背後所偏好的政策立場(position)則有不一致的風險,亦即與「正面情緒言論偏向贊成,負面情緒言論偏向反對」的經驗法則有所偏離(蕭乃沂、黃東益,2016),更遑論在政策審議過程中講究的論述(argument)與證據(evidence)。
另一方面,隨著日益趨向複雜的網路輿情分析演算法,已有相關論者警惕大數據分析存在著資料來源與內容偏頗、以及有意或無意地的演算法偏見風險,研究與實務者應避免過度依賴其自動化演算成果(Janssen and Kuk, 2016),除了透過公開與跨領域展示交流機制,透過虛擬與實體空間中人類與機器互動與互補過程,方能實質貢獻於公共政策審議的過程與成果(Cai et al.,2017)。
資料來源:蕭乃沂等(2014)。
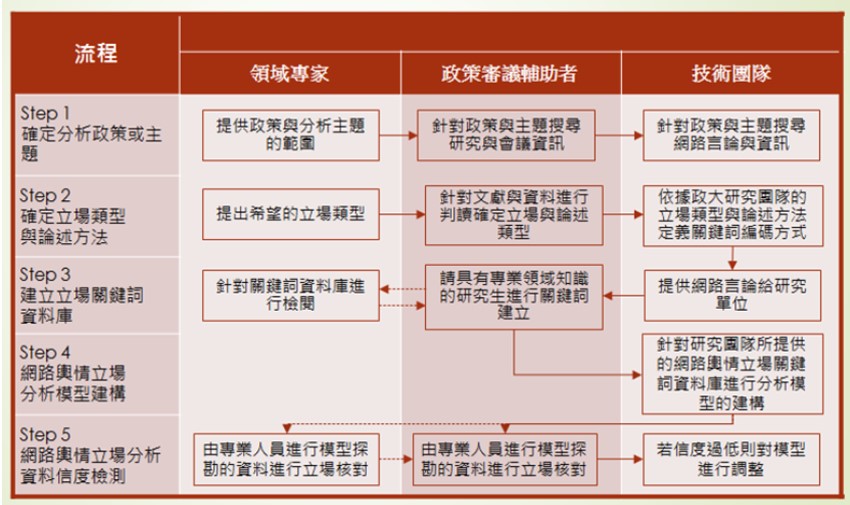
為了提升網路言論的情緒與立場間的一致性,蕭乃沂、黃東益(2016)以核能安全議題為案例,透過政策審議輔助者居間,串連領域專家與網路輿論分析的技術團隊(如圖 2),確實將兩者的一致性提升至七成的水準,雖然該研究尚未觸及公共政策審議所需的論理與證據層次的萃取分析,也已累積充足的經驗成為進一步整合虛擬與實體的公民參與程序(如 Cai et al., 2017)。
資料來源:蕭乃沂、黃東益(2016)。
上述關於網路輿論分析的研究成果,也是近年來諸多相似概念諸如人機協作(human-machine collaboration)、可解釋的人工智慧(explainable AI)、協作智慧(collaborative intelligence)、或擴增智慧(augmented intelligence,也是 AI)應用於特定公共政策議題的案例(Accenture, 2018; Wilson & Daugherty, 2018),亦即透過領域專家與利害關係人的表態與解讀,並透過自然語言與機器學習演算法的輔助,透過人機協作連結實體意見及網路輿論,企圖提昇兩者的交互對話,並且也更全面地納入決策分析的架構中,以兼顧特定政策議題的政策制訂需求、領域專業、與公民審議品質。
從技術面向來看,上述進展也受惠於近年來自然語言處理(natural language processing, NLP)應用日趨廣泛,機器在資料處理上日趨優異的能力使得我們能夠對網路巨量資料(big data)進行分析。目前 NLP 的用途非常廣泛,包含偵測詐騙郵件、情緒分析、網路搜尋建議修正、詞類標示、機器翻譯、語音辨識、人名辨識擷取、摘要文本大綱、以及句法分析等。NLP 模型建構係以人工智慧的方法訓練機器,使得機器能夠依據內容判別「網路輿情民意對核廢料議題之立場」。實務執行時,在將資料餵入(input)機器前,需要先透過人工方式編碼標註(label)網路輿論內容(例如議題相關性﹑正負面情緒﹑贊成反對立場等),並提供機器判別所需的特徵(例如支持以上標註的關鍵詞﹑語句等)。Kim等人(2013)即運用 NLP 建模,分析網路餐廳評論文本資料及美國政府的衛生檢查紀錄,最終模型能夠成功預測衛生檢查通過與否的比率高達 82%,顯示網路輿情文本資料確實能夠輔助做為政策環境評估的重要參考。
貳、網路輿情分析應用於決策現況
本文作者與研究團隊曾於 2019 年針對我國備受關注且爭議的核廢料議題進行網路輿情蒐集分析,企圖探知民眾在網路上對於核廢料處理相關議題的情緒意向。首先透過資料搜集步驟、資料來源、資料品質考量後,蒐羅自臺灣地區九成以上公開之討論區各主題之分板、社群網站(包括:Facebook、PTT、Twitter、Instagram、D-card 等)之互動與形象經營問答網站之提問與回應、部落格文章或文字資料、新聞媒體與專欄,並且預先將其以關鍵詞時間等多維度予以索引分類與儲存。再針對網路輿情內容篩選主題、聲量趨勢來源呈現、關鍵字探索與分析、重大事件(events)討論,最終應用於政策討論場域之中。研究發現:邊緣議題必須跟隨政治事件共同產生聲量、網紅(key opinions leaders,KOL)動態引導風向以致弱化在地民意和關注焦點等網路獨特現象。
此外,為探究特定核廢料政策、議題於媒體再現的效果,網路輿情分析必須搭配特定時間發生的特定事件,尤其是重大事件,才有足夠的討論聲量,以進行媒體再現效果的分析。故研究者先以核廢料主題進行搜尋,多次嘗試,即撈取資料,並以人工判讀辨識其資料筆數與品質,以清除雜訊。隨後搭配核廢料重要事件發生時,針對搜尋結果解讀。結果發現核廢料主題下的支分,如乾貯、除役、原住民等,在資料搜尋期間(2019/10 ~ 2020/3),因為發生蘭嶼貯存場補償金事件(2019 年 11 月),以及建議候選場址之一的台東達仁鄉南田村(排灣族地區)火箭試射事件(2020 年 2 月),網路上熱門討論的面向脫離不了原住民。最後便篩選設定以本案「核廢料」為主軸,以及次議題「原住民」進行網路輿情分析。
常見的網路輿情分析包含下列重要觀測指標:
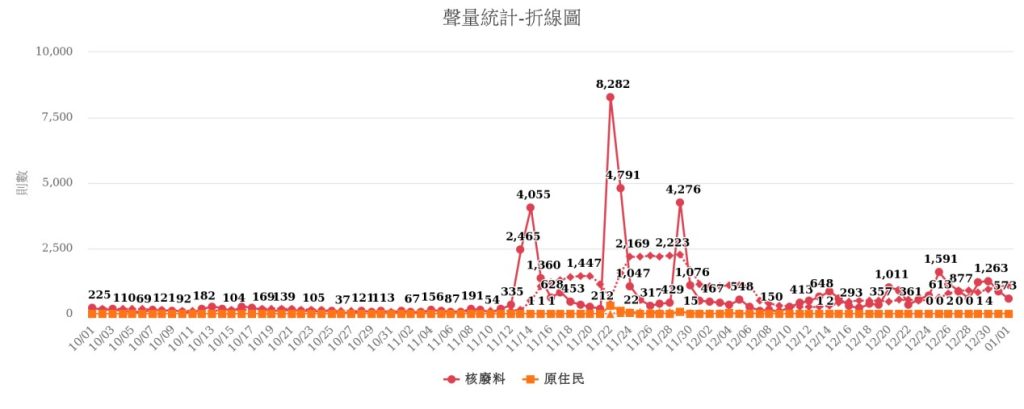
1、聲量分析:聲量數(聲量佔比)即分析各族群討論主題的網路輿論聲量(如圖 3),提供特定族群區隔的聲量數,藉以了解討論最多該主題的族群區隔為何。透過語意分析自動擷取與該主題相關關鍵字分析,讓使用者掌握該主題的重點議題。
2、情緒分析:使用正負面情緒詞庫輔以文章長度、字詞出現佔比等概念,透過機器學習機制,進行正面/負面/中立三個類別的自動分類學習,產出單篇文章的情緒分類判讀,呈現正負情緒比(如 P/N 比 = 正評數 / 負評數),其趨勢圖可用於檢視每天情緒聲量之消長變化。
3、來源分析:針對主題(即眾多關鍵詞組之組合),根據來源佔比呈現聲量分布狀況,用於比較主題輿情分布之特性,並可區分五大來源,按照每日時間趨勢呈現,可參考聲量高峰,解讀不同來源組成聲量之原因(如圖 4)。
4、趨勢分析:趨勢圖可選擇一個或多個主題,將聲量依日期呈現其趨勢變化,可用於呈現主題間聲量消長狀況,或事件發生前後聲量差異等,掌握聲量變動趨勢。最後,針對以上不同的分析,進行結果的詮釋與解讀,以全面性瞭解不同世代網民對於論述、傳播途徑、情緒、立場、聲量、關鍵詞、討論趨勢之差異。
資料來源:本研究自行整理。
資料來源:本研究自行整理。
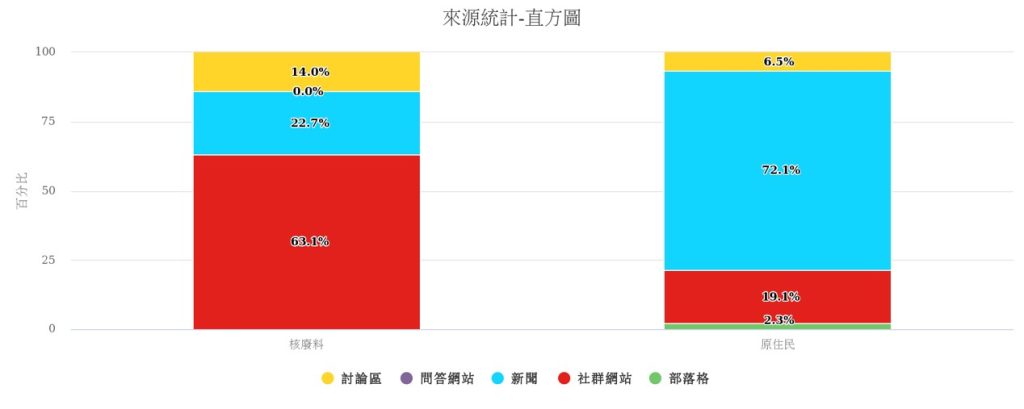
網路輿情分析之呈現方式,包含聲量趨勢,藉此瞭解網路上的討論,隨不同時間、發生不同的事,而被關注、被討論人數、次數等數量上的消長。再者亦針對聲量的來源進行分析,而來源可略分為新聞、論壇、社群媒體等,當時監測之聲量來源亦有明顯差異,其中核廢料主題的網路輿論明顯來自於社群媒體,而原住民主題的網路輿論多數則來自於新聞。簡言之,核廢料的討論,在社群網站,也就是互動性、即時性、回應性都比較高的地方,不一定要伴隨重大事件,可以輕易地被挑起網路討論;而子議題「原住民」卻是在新聞,意味著必須伴隨外在事件的發生,引起社會輿論為主的地方被討論。
此外,透過多個斷詞機器人(演算法)來判斷每一個詞彙的重要程度,公式為「詞頻*加權分數」。詞頻為詞彙出現的次數,加權分數則是每一個機器人使用一種演算法,經過多個機器人進行斷詞後,採用多數決投票法(majority voting)來決定一個詞彙的權重,被越多演算法斷出的詞彙其權重越高。透過這樣的演算法,能夠了解特定事件在特定時段發生時,所被運用以進行討論的線上政策論述方式,以及其所使用的關鍵詞彙或特徵句。以 2019 年的蘭嶼核廢料補償金案例為例(如圖 5),核廢料的貯存、賠償金補償金的爭議、以及執政黨都是該段時間的討論熱點。有趣的是,從該事件的觀測報告中可窺知即便執政黨政府強調,補償金的發放係依據轉型正義的精神進行歷史脈絡的調查,並對於當地住民進行補償的制度,且尤其重視原住民達悟族在歷史脈絡中的定位及被侵犯的權益損害。雖此,透過關鍵字詞分析,原住民歷史的真相調查(排名第 31 位)並未被廣泛討論。反之,該政策的核心,包含補償金(排名第 22 位)及補償要點(排名第 48 位),都比起歷史真相調查引發更廣泛的網路討論聲量。基此,透過網路輿情分析方法,可觀察到當地居民的訴求焦點,雖然多仍聚焦於核廢料的搬遷,但我們發現在網路討論的浪潮下,當地住民的真實需求,未必能夠真實被反映。
資料來源:本研究自行整理。

參、立場分析初探研究
網路輿情分析結合了傳統議題分析方法以及資通訊技術的進展,其自動化快速資料量大的特性,除了關注議題聲量、情緒/好感度、發言管道、網紅效應、特定重大事件影響等交叉呈現,也能夠透過自然語言處理分析(NLP)技術,針對發言者的論述建立模型加以判斷其正反立場。作者與研究團隊在先前研究中,曾試驗領域專家在意見探勘流程中,究竟扮演什麼樣的角色以及如何在自己所處的位置上進行專業知識的運用發揮,也回顧人機協作的機制,試圖在傳統公共政策分析中更有建設性地應用網路輿情分析的優勢。
基於 NLP 的語意分析模型可以快速的提供大規模的民意調查結果,並且依據其偏好、立場、情緒,進行幾近即時的成果展現,此研究與實務在情緒分析(sentiment analysis)已有明顯之成效並已大規模應用,然而,基於人類論述語言的高度複雜性,對於公共政策(尤其是高度爭議)特定議題的立場的分析與呈現仍需後續研究持續努力。
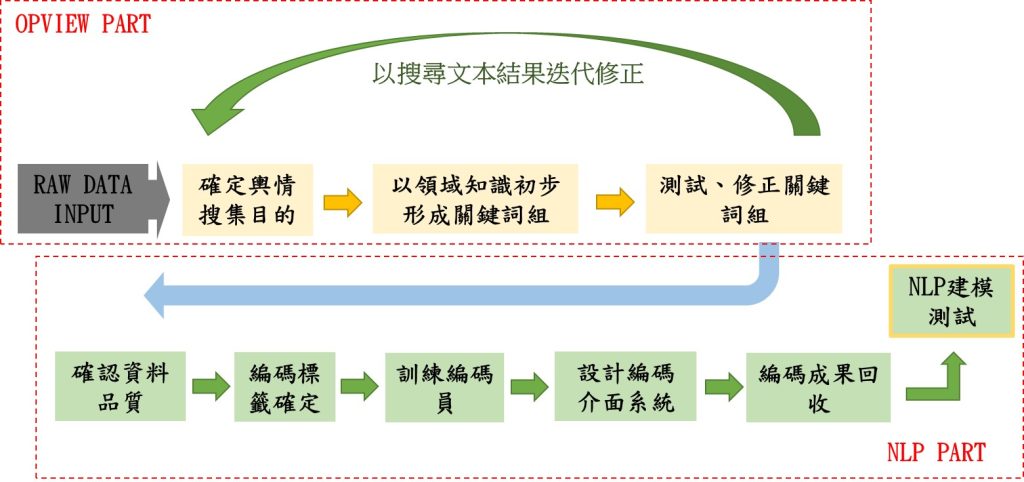
以核能政策為案例,作者與研究團隊曾規劃執行以下流程進行初探性研究(如圖 6):
- 標記文本標籤:召集跨領域專家共同討論編碼標籤對於領域知識意義之解讀及實際編碼工作之可行性。
- 編碼樣本數確認:跨領域專家共同討論如何分類不同的樣本特徵群,並確認各群樣本大小,經討論後包含社群主文、社群回文、新聞主文、論壇主回文。
- 編碼員資格:需熟悉公共事務,並對能源政策有相當程度之認知,本研究以公共行政系學生曾修習環境政策相關課程者中,挑選具有熱忱之優秀學生擔任。接續訓練編碼員,召開工作坊會議提供編碼指導及領域知識的訓練。
- 邀請資科系專才設計編碼介面系統,以提升編碼效率與品質。利用 Dataturks 作為此計劃的標記工具,希望能以更淺顯易懂,易於標記的介面使編碼員操作更為方便,減少編碼員的負擔,提升標記工作 的效率[3]。
- 標記工作為先於文章中標記哪些句子為支持核能句子、反對核能句子、提及核廢料句子。
資料來源:本研究自行整理。
本案例使用目前主流的自然語言處理模型 BERT(Bidirectional Encoder Representations from Transformers)作為基礎,BERT 為 Google 所開發並開放免費使用的自然語言處理預訓練(pre-training)技術,以利於語意分析的研究與實務工作者方便地建構 NLP 模型,節省了訓練語意判斷所需的資源[4]。
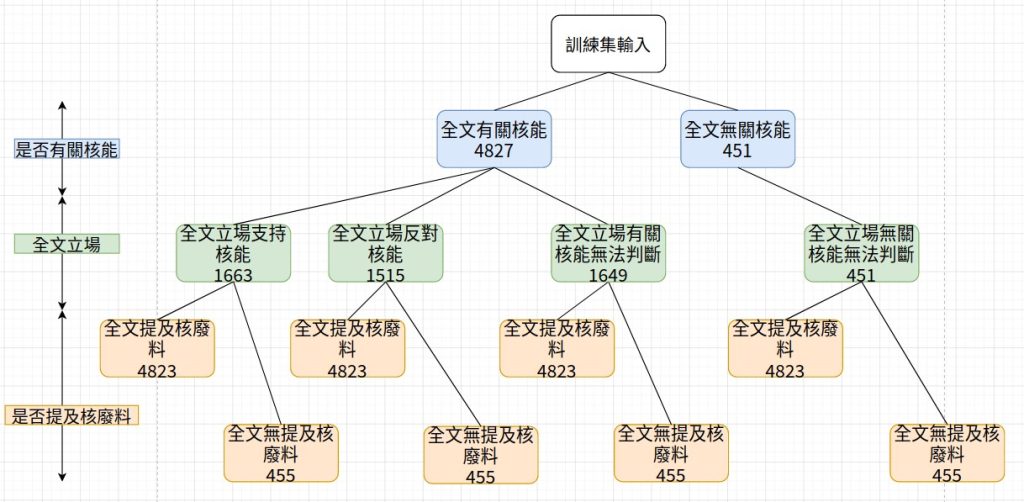
如果將此語意判斷任務視為一個三階層式的分類問題(成果展示如圖 7),在第一層分類問題先判斷一則網路留言(主文或回文)是否有關核能。第二層分類問題繼承第一層分類結果,若留言有關核能,則判斷此留言立場為支持核能、反對核能、或無法判斷立場;若留言無關核能,則判斷此留言立場為無法判斷,因此「無法判斷」立場標籤分為「有關核能無法判斷」及「無關核能無法判斷」。第三層分類為判斷留言是否有提及核廢料,此層分類與之前兩層分類互為獨立階層,不受前兩層分類影響。本研究將訓練模型所需的留言資料(主文、回文)分為訓練集以及測試集,利用 BERT 預訓練模型將訓練集資料轉換為模型可讀之向量,藉由句子輸入、輸出之配對(即由編碼員所標記對於核廢料相關文章或回文的立場),讓機器模型從大量的輸出入配對中學習,建立輸入與輸出之關聯。
資料來源:本研究自行整理。
最終在本次初探性研究中,在判斷是否提及核廢料與是否有關核能這兩個任務上,模型顯示出頗好的效能(如表 1),不論是 Accuracy、Precision、Recall或是最主要的 F1 值都能達到九成以上[5]。然而在核能政策立場判斷上,其各項模型判斷成效指標僅落在 0.62-0.68 之間,顯示除了標籤種類變得更為複雜外,發言者各式各樣的論述方法,都可能造成 NLP 演算法在網路輿論立場的誤判。
表 1:核能政策議題-自然語言處理語意模型初探性研究成果
| 是否有關核能 | 全文政策立場 | 是否提及核廢料 | |
|---|---|---|---|
| Accuracy | 0.9717 | 0.6208 | 0.9832 |
| Macro –F1 | 0.9178 | 0.6582 | 0.9563 |
| Precision | 0.9337 | 0.6679 | 0.9637 |
| Recall | 0.9033 | 0.6517 | 0.9493 |
資料來源:本研究自行整理。
肆、討論與展望
前文以我國備受關注與爭議的核廢料議題作為案例,除了規劃分析流程並以實作呈現初步成果,作為公共政策領域的企圖在於善用自然語言處理 NLP 於網路輿情的情緒與立場判斷,此涵蓋公共政策分析、資訊、資料科學與核廢料議題的跨領域研究經驗,也值得廣義社會科學領域的研究與實務的參考。
本文案例與分析雖然主要以量化成果展現,實際上質性領域知識是串連網路輿情分析各階段不可或缺的元素。在圖 2 與圖 6 的操作流程中,不論作為情緒或立場的判斷,從初始的關鍵詞選擇與試誤、合理資料撈取期間、重大事件的研判、網路輿情來源管道,到模型訓練調校時的輿論資料篩選、正負情緒研判、正反立場研判、模型績效研判,以及文本資料補充等,皆需要跨專業領域與量化質性資料的佐證與對比,這是量化或客觀演算法外表下網路輿情作為文字探勘分析本質的主觀特質。
如果將上述兼具質性量化雙重性提昇到研究方法(research methods)或方法論(methodology)的層次,此跨域研究就有更多靈活的可能運用。例如其他文本來源如領域專家意見、國會質詢紀錄、以及散見於其他非網路來源的論述文字等,即可作為研擬核廢料關鍵詞時的參考;針對一般民眾的核廢料民調問卷題目,也可參考演算法斷詞或訪員標記關鍵詞或語句(包括反映網民的情緒或立場);對於「意料之外」的負面情緒與反對立場,演算法斷詞或訪員標記或許能提供政策主管機關更為精準的政策溝通基礎。
展望未來網路輿情分析的發展,一方面應追求並善用資料蒐集與分析方法的三角檢證(triangulation of data sources & analytics),跨越專業領域、質性量化方法、與研究實務取向的藩籬;另一方面也應該讓操作流程(如圖 2、圖 6)更為具體且易於解釋,尤其是關於模型訓練與相關演算法,其諸多參數調校如何以領域知識合理解讀,以追求嚴謹研究與實務應有的可重複性,並呼應演算法與廣義人工智慧的可解釋性訴求(AI explainability;Accenture, 2018),終究將有益於整合網路輿情分析成為循證決策與政策分析(evidence-based decision making and policy analysis)的新興方法。
參考文獻
Accenture. 2018. “Explainable AI: The Next Stage of Human-Machine Collaboration,” https://www.accenture.com/us-en/insights/technology/explainable-ai-human-machine (accessed: December 2, 2022).
Cai, B., Geng, Y., Yang, W., Yan, P., Chen, Q., Li, D., and Cao, L. 2017. “How Scholars and the Public Perceive a “Low Carbon City” in China,” Journal of Cleaner Production, vol. 149, pp. 502~510.
Cai, W., Ma, M., Shen, L., Ren, H., and Ma, Z. 2017. “How to Measure Carbon Emission Reduction in China’s Public Building Sector: Retrospective Decomposition Analysis Based on STIRPAT Model in 2000–2015,” Sustainability, vol. 9, no. 10: 1744.
Janssen, M., & Kuk, G. 2016. “The Challenges and Limits of Big Data Algorithms in Technocratic Governance,” Government Information Quarterly, vol. 33, no. 3: pp. 371~377.
Kim, Jeong, D., J., Kim, G. N., Heo, J. U., “On, B. W., and Kang, M. 2013. A Proposal of a Keyword Extraction System for Detecting Social Issues,” Journal of Intelligence and Information Systems, vol. 19, no. 3, pp. 1~23.
Luna-Reyes, L. and M Najafabadi, M. 2017. “Open Government Data Ecosystems: A Closed-loop Perspective,” Proceedings of the 50th Hawaii International Conference on System Sciences.
Noet, L. 2017. “Autour de Gaston Castel. Promotion d’une Sculpture Monumentale Parlante à Marseille,” In Situ. Revue des Patrimoines, vol. 32: https://journals.openedition.org/insitu/15391 (accessed: December 12, 2022).
Wilson, J. and P. R. Daugherty. 2018. “Collaborative Intelligence: Humans and AI Are Joining Forces,” Harvard Business Review, https://hbr.org/2018/07/collaborative-intelligence-humans-and-ai-are-joining-forces (accessed: December 2, 2022).
蕭乃沂、陳敦源、廖洲棚,2014,「政府應用巨量資料精進公共服務與政策分析之可行性研究」,國家發展委員會委託研究報告。NDC-MIS-103-003。
蕭乃沂、黃東益,2016,「核能議題的政策論證與風險溝通:網路輿情分析應用」,科技部專題研究計畫。MOST104-NU-E004-001-NU。
[1] 電子郵件信箱:[email protected](通訊作者)。
[2] 電子郵件信箱:[email protected]。
[3] Dataturks 係開源性質的資料標註網站(網址:https://docs.dataturks.com/),透過人性化介面服務,使得任務管制者得以在不具資訊科學背景的條件下,進行資料標住專案的管理分工及監控進度,且當資料標註完成後能以圖形化介面呈現統計資訊,並產出電腦能夠運算的資料格式。
[4] BERT 簡介如網址,https://cloud.google.com/ai-platform/training/docs/algorithms/bert-start。2022/12/2。
[5] 此四個指標均為自然語言處理中評估模型性質的重要指標,主要係透過實際標註結果與模型預測結果的對照,產出混淆矩陣(confusion matrix)並進行運算,透過不同指標得以解讀模型過度擬合(overfit)或擬合不足的根本原因,藉以提升模型效能。Accuracy 為準確率,主要代表模型預測正確數量所占整體的比例。Precision 則為精確率,意即被預測為真的資料,其所真實為真的比率。Recall 係召回率,代表真實為真的資料,有多少被模型所成功預測。F-1 則為 Precision與 Recall 的調和平均數,藉以較為全面的反映出模型的效能。